

How to build RAG systems in 2026: Hands-on expert insights


Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with an organization’s own knowledge bases to deliver accurate, secure, and reliable AI outputs. Instead of relying on training data alone, RAG systems retrieve relevant information from trusted sources and use it to generate responses, which makes RAG a practical foundation for enterprise AI, internal tools, and customer-facing LLM applications.
In this guide, Darya Krauchenia, our Senior AI Expert, shares hands-on insights into RAG use cases, reference architectures, and practical steps for building enterprise-grade RAG systems. The article is designed for teams building AI solutions with LLMs, including internal assistants, search experiences, and knowledge-driven systems.
Key takeaways
- RAG is an architectural approach that shapes how generative systems work with external knowledge. It starts with use case evaluation and extends to data preparation, access control, and observability.
- RAG is well-suited for enterprise-scale systems, as it enables handling large and fragmented datasets with access control and corporate security policies applied.
- RAG enables the use of AI for a specific scenario without retraining on corporate data.
RAG use cases for enterprises
A RAG system serves as an intelligent knowledge layer for enterprises. It allows users to quickly access the information they are authorized to see across documents, systems, and teams. Within an enterprise environment, this capability supports a wide range of practical use cases:
|
Use case |
Quick access to |
|
Customer support |
Product documentation, ticket history, troubleshooting guides, common resolutions and edge cases, CRM data, draft replies |
|
IT incident analysis |
Logs, history of past incidents, how-to guides, internal wikis |
|
Billing and payment analysis |
Invoices, payment documents, reconciliation notes, and dispute records |
|
Contract analysis |
Contract repositories |
|
Policy and regulation copilots |
Regulatory texts and legal memos |
|
Sales enablement |
Corporate decks, case studies, CRM data, corporate policies |
|
HR assistants |
Onboarding materials, corporate policies, handbooks, role-specific guidelines, and benefits |
|
Procurement and vendor risk assessment |
Vendor assessment lists, contract summaries |
|
AI coding assistants |
Architecture documentation, code repositories, code documentation |
Compared to manual search, RAG systems return results faster and with higher relevance as they retrieve information based on meaning and context, not exact keywords. Beyond these advantages, Darya adds:
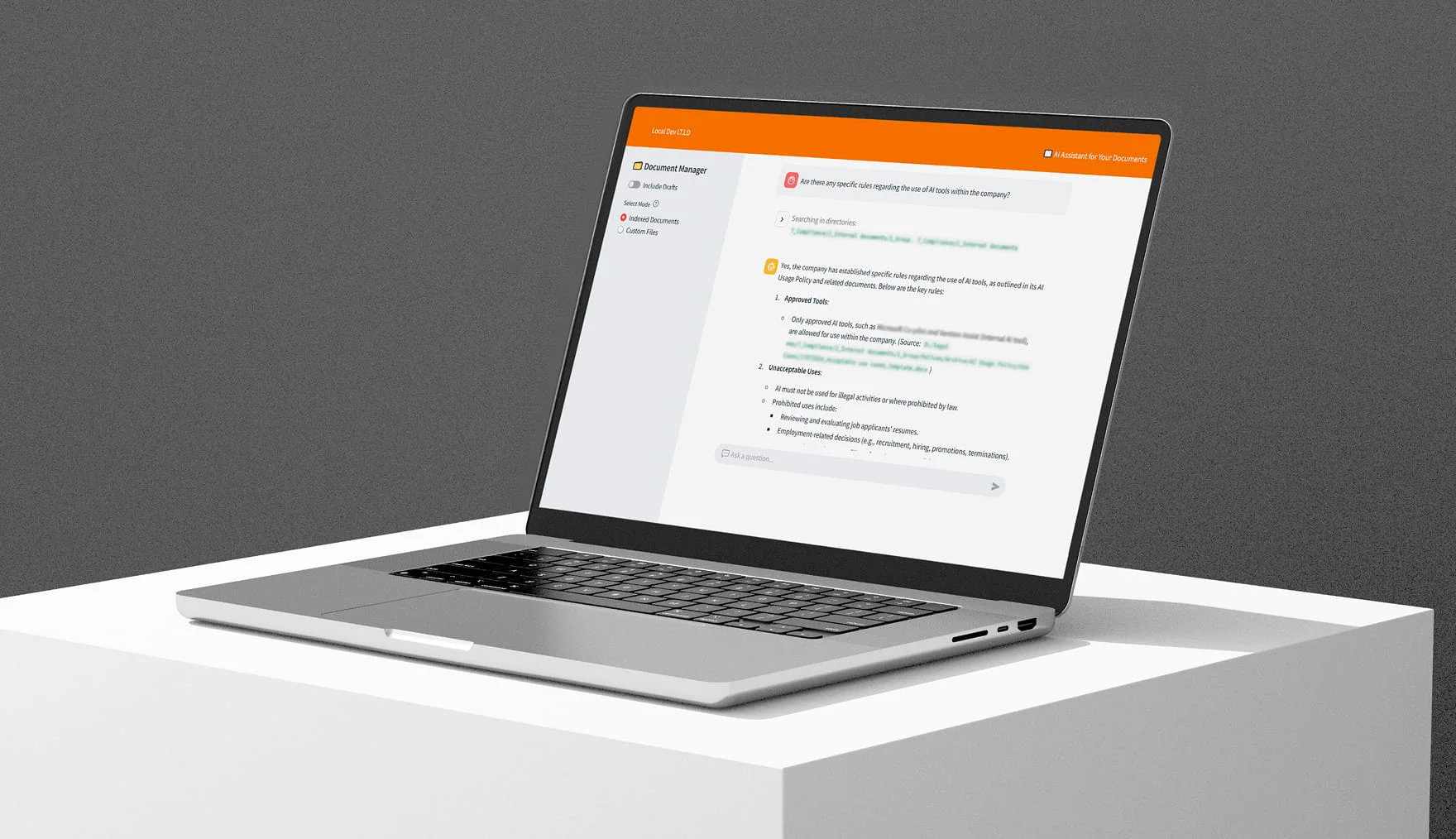
“In many cases, RAG is the most effective approach for search across thousands of documents because it stores semantic embeddings and retrieves information through vector search rather than scanning the entire database. In one of our recent internal projects, where retrieval was required across 15,000 folders containing more than 55,000 legal documents, RAG proved to be the only practical choice.”
Sample RAG architecture
A RAG system is built as a set of connected layers that control how user queries are processed, how data is retrieved, and how context is passed to a large language model. The layered structure ensures responses remain relevant, permission-aware, and tied to enterprise data.
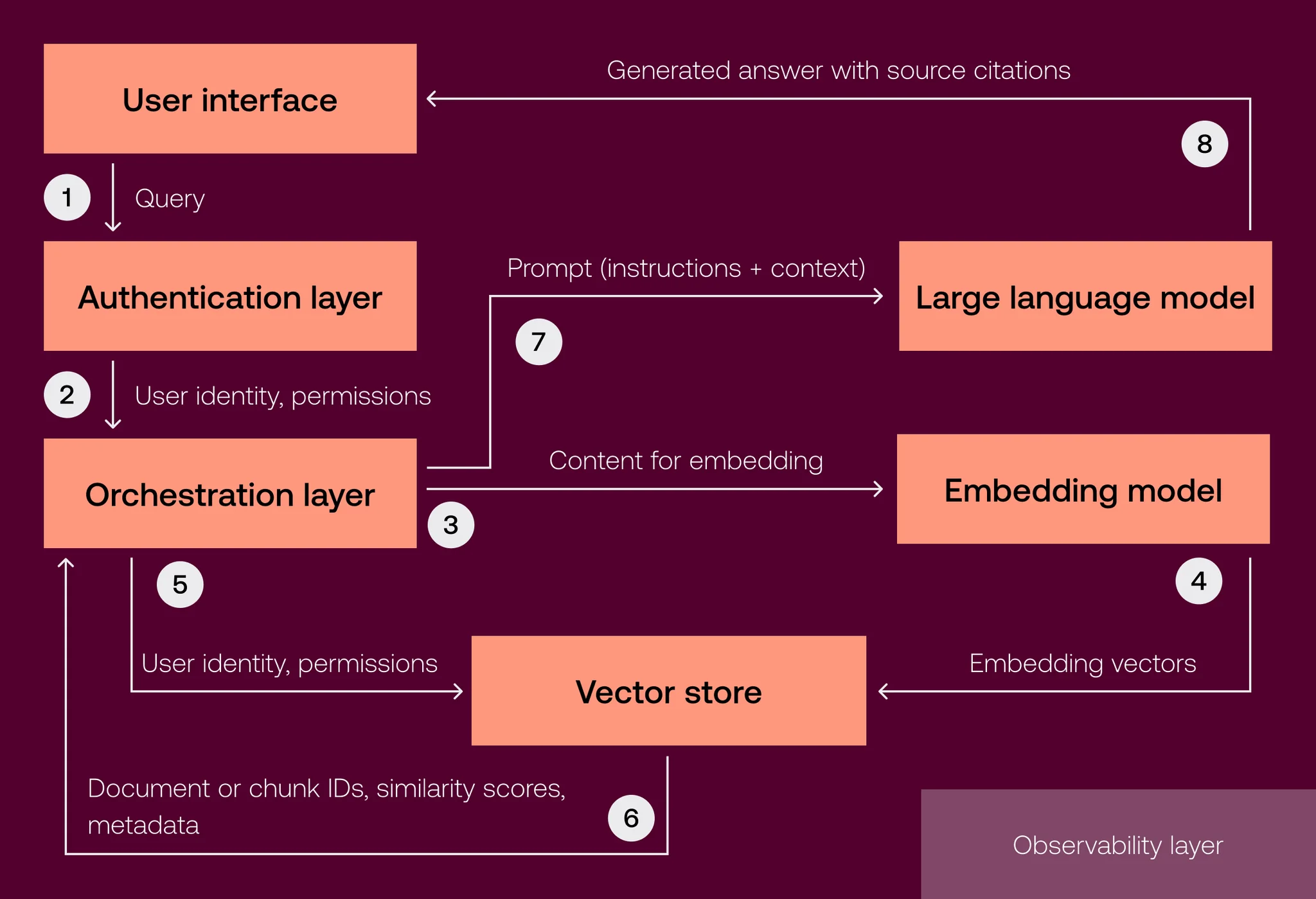
Architecture blocks and responsibilities
|
Architecture block |
Business logic |
Technology side |
|
User interface |
A RAG system begins when a user, or an AI agent in the case of agentic RAG, submits a query. |
|
|
Identity and authorization service |
The request is passed to the organization’s identity and authorization service to verify a user’s or AI agent’s access rights. Say, a user requests “Fetch the information on our experience within the fintech domain,” access checks are applied before retrieval starts. |
|
|
Orchestration |
The orchestration service processes an initial query and transforms it to facilitate a successful retrieval from the vector store. This is why “Fetch the information on our experience within the fintech domain” is transformed into structured signals such as intent, domain, and desired content types.
The orchestration service then receives the prepared context, combines it with the transformed user request, and sends the combined information to the LLM. |
|
|
Embedding model |
The embedding model converts queries and documents into vector representations. Documents are embedded during ingestion or reindexing, while each incoming query is embedded at retrieval time to enable semantic search. |
|
|
Vector store |
This layer stores vectors and chunked representations of corporate documents enriched with metadata, such as access-control labels and source IDs. Vector representations that represent semantically similar chunks, for example ticket histories, customer communication threads, or contracts, are positioned closer in the embedding space. |
|
|
Large-language model (LLM) |
The LLM receives only the approved, permission-filtered context assembled from the retrieved chunks. Because the response is grounded in enterprise data rather than the model’s internal knowledge, the output is highly relevant and contextual. Enterprise RAG systems often support citations, allowing each part of the answer to be traced back to specific source documents.
|
|
|
Observability and monitoring layer |
The monitoring layer tracks incoming queries, the system’s internal decisions, the IDs of retrieved chunks, and the final output. It helps teams evaluate retrieval quality, diagnose failures, monitor costs, and ensure compliance with security and regulatory standards. |
|
Step-by-step guide to implementing RAG for enterprise
RAG project planning
- Prioritize use cases that offer the highest business impact and align with your enterprise goals.
- Analyze whether each of the selected use cases satisfies your organization’s compliance and security requirements and confirm that they are technically and operationally feasible.
- Define KPIs to measure the initiative's success. Examples include tracking time savings compared with manual search and the rate of first-contact resolution.
- Decide between internal development and project outsourcing.
- Choose between on-premises and cloud deployment after evaluating security, compliance, and cost constraints.
Data preparation for RAG-based search
- Audit internal and external sources, classifying them to define how each source can be transformed into numerical representations, or embeddings.
- Define the retrieval strategy, choosing between a vector database, keyword- or metadata-based search, or a hybrid approach.
- Together with subject-matter experts, define representative question–answer pairs that reflect the types of queries users are likely to ask and the responses they expect.
- Tag available data with user roles and sensitivity markers.
- Determine what can be safely exposed to the LLM and which data requires masking.
- Build a high-quality labeled dataset to verify that the RAG system retrieves relevant content and applies it accurately in its answers.
- Create a vector store with the prepared data and metadata.
- Maintain data lineage and versioning so each retrieved chunk is traceable back to its source system and update history.
- Implement pipelines for updates using change data capture or event triggers, so that semantic documents and embeddings remain up to date without full reindexing.
RAG system design and development
- Architect the RAG solution to accommodate increased workloads and new data sources so that performance and uptime are not compromised as the system evolves.
- Design and implement data vectorization, retrieval, and model integration pipelines.
- Choose the approach to triggering embedding refreshes and re-indexing cycles (schedule-based, CDC-based, or event-driven).
- Choose a vector store, e.g., Weaviate, Pinecone, and FAISS.
- Select an open-source or commercial LLM according to your requirements.
RAG testing
- Run tests for recall, relevance ranking, and coverage. The essence is to verify whether the system identified the most relevant chunks and whether their number was sufficient to generate a satisfactory answer.
- Simulate real-life user behavior to test the system’s capabilities. With multi-turn testing that focuses on a series of questions and follow-ups rather than isolated queries, you can test memory and context window management.
- Confirm that the system avoids hallucinations and handles refusals. For this purpose, intentionally send vague or contradictory queries and requests that the system shouldn’t answer at all.
Deployment and monitoring
- Load embedding vectors and related metadata into memory before the first user query. Otherwise, the initial requests will be slower while the system warms up.
- Establish tight control over both generation and embedding model versions. If either model silently changes (e.g., due to the provider’s automatic upgrade), the RAG system may start generating incorrect answers and citations.
- Continuously monitor the system's performance metrics (latency, accuracy, user satisfaction).
- Establish a feedback loop for reporting incorrect answers or other glitches.
Insights from our expert
“User trust in a RAG system rarely breaks because of the model itself. It breaks when documents change, and access rights evolve, but the system fails to reflect those updates. That’s why teams should plan for incremental updates and selective re-indexing as early as the system design stage.”
Are you looking for a reliable delivery partner?
• Design
• Development
• Testing
• Deployment
• Support and evolution
We build RAG systems both for clients and for our own internal teams, so we know the process end to end, and we’ll help you tick all those boxes.
Trends for RAG in 2026
Agentic RAG systems
In agentic RAG systems, an AI agent is responsible for triggering retrieval. As part of its reasoning and planning loop, the agent repeatedly queries enterprise knowledge sources to gather information, validate actions, and complete multi-step tasks. Over time, RAG evolves from a simple question-and-answer mechanism into an intelligent workflow engine that can support more complex enterprise processes.
Vention recognized the potential of agentic RAG systems early and built one for internal use. As a result, our marketing team now spends 40% less time searching for internal information with an internal agentic RAG system.
Multi-modal architectures
In enterprise environments, data is usually stored in multiple formats (text, images, structured tables, etc.). Multi-modal architectures address this complexity by combining different AI models optimized for specific data types and tasks.
The orchestration service selects the appropriate embedding model and retrieval pipeline based on the incoming query and the target content type. After that, it routes the request to the corresponding model and index, ensuring retrieval remains accurate and efficient across heterogeneous data sources.
Hybrid retrieval
Hybrid retrieval is widely adopted in enterprise RAG systems. The combination of vector search with keyword- and metadata-based retrieval enhances the quality and relevance of retrieved context, positively impacting overall response quality.
Popular RAG technology choices in 2026
|
RAG architectural layer |
Leading tools in 2026 |
|
Orchestration |
|
|
Vector database |
|
|
Embeddings and LLMs |
|
|
Monitoring |
|
Cost factors for custom RAG solutions
Custom RAG solutions are built around specific enterprise requirements, which directly affect both development and operating costs. Beyond infrastructure and model expenses, several less visible factors can significantly influence the final price and long-term total cost of ownership.
Number of supported use cases
Each additional use case increases overall cost. While core RAG infrastructure is often shared, every use case typically requires its own data sources to integrate, unique business logic, and evaluation criteria. These differences drive additional design, development, testing, and maintenance efforts.
Complexity of the RAG pipeline
The cost increases with the number of operations performed per request. The list may include query transformation for facilitated retrieval, re-ranking, prompt assembly, multiple model calls, or citation generation.
The number of users
As the number of users grows, the RAG pipeline must process more concurrent requests. Higher load places additional demands on infrastructure, which directly increases operational costs.
Model and tooling licenses
Tools may come with usage-based or subscription fees. The main challenge is not selecting the cheapest option, but choosing tools that balance price, capability, and reliability. For example, a lower-cost tool can fail to guarantee the required level of data security. Meanwhile, open-source alternatives are free, but they may require additional effort to achieve consistently high-quality output.
Maintenance costs
Some factors emerge over time and impact the long-term total cost of ownership. Data maintenance, re-indexing embeddings, and performance optimization are required to keep the RAG system accurate, reliable, and cost-efficient as usage and data volumes grow.


