Client
To streamline legal data retrieval across signed contracts, active agreements, and related clauses, Vention built an internal RAG platform for its Legal department.
The platform helps our Legal professionals find accurate information quickly, without having to dig through multiple document versions.
Project description
At the moment, Vention’s Legal department manages more than 50,000 unique documents across multiple regions, including the US, UK, DACH, and Asia. Many of these documents exist in multiple versions that continue to change as client relationships evolve and teams operate across different locations.
Even with documents well organized across folders, legal specialists still face numerous challenges when searching for specific information, including:
- Similar concepts are often expressed using different wording across documents, without exact matches
- Relevant answers are sometimes spread across several documents rather than stored in one place
- The precise legal phrasing required for a query is not always clear in advance
Manual searches under these conditions take significant time and increase the risk of missing important details.
To support faster access to both historical and current contract data through natural language queries, Vention’s AI team designed, tested, and implemented an internal RAG platform for the Legal department.
Our core responsibility is keeping legal operations responsive and scalable in a fast-moving environment. As the company grows, Legal is expected to support more teams, more decisions, and more documentation, which creates constant pressure to deliver accurate legal input without compromising quality or risk control.
Legal work continues to change, so spending less time on repetitive tasks such as locating documents, identifying clauses, tracking updates, and manual compliance checks becomes increasingly important, particularly when information is spread across multiple files and formats.”

Tatsiana Bialiayeva
Head of Legal at Vention
Our solution
Vention’s AI experts teamed up with the Legal department to design, develop, and deploy a modular RAG platform. The solution enables legal teams to retrieve information directly from documents stored across the entire file system. It relies exclusively on the actual content of those documents rather than on any external or pre-trained model knowledge.
The platform includes three logical layers:
- A user interface that supports simple and intuitive interaction
- A request processing layer that handles queries and context
- A core RAG layer responsible for retrieval and response generation
User interface
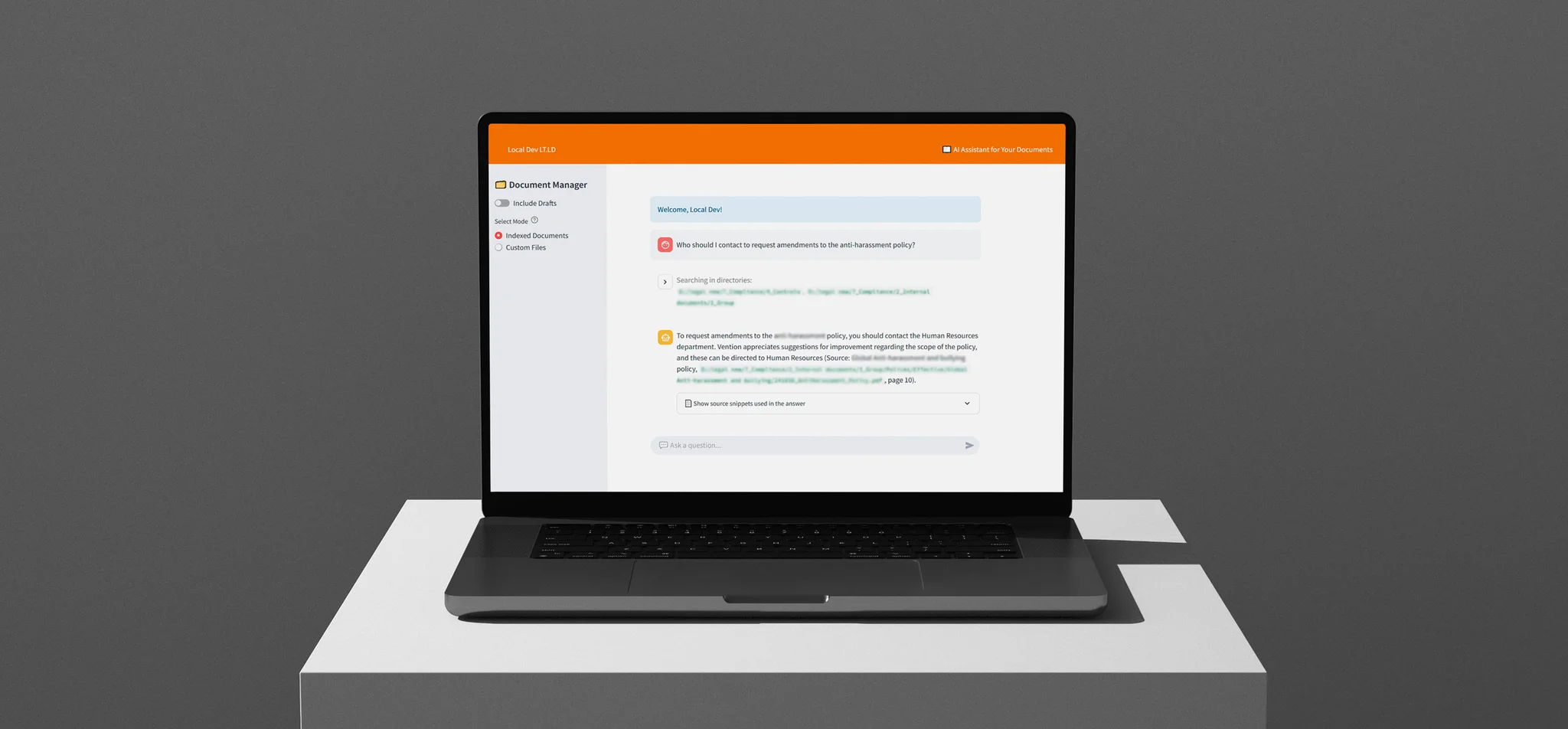
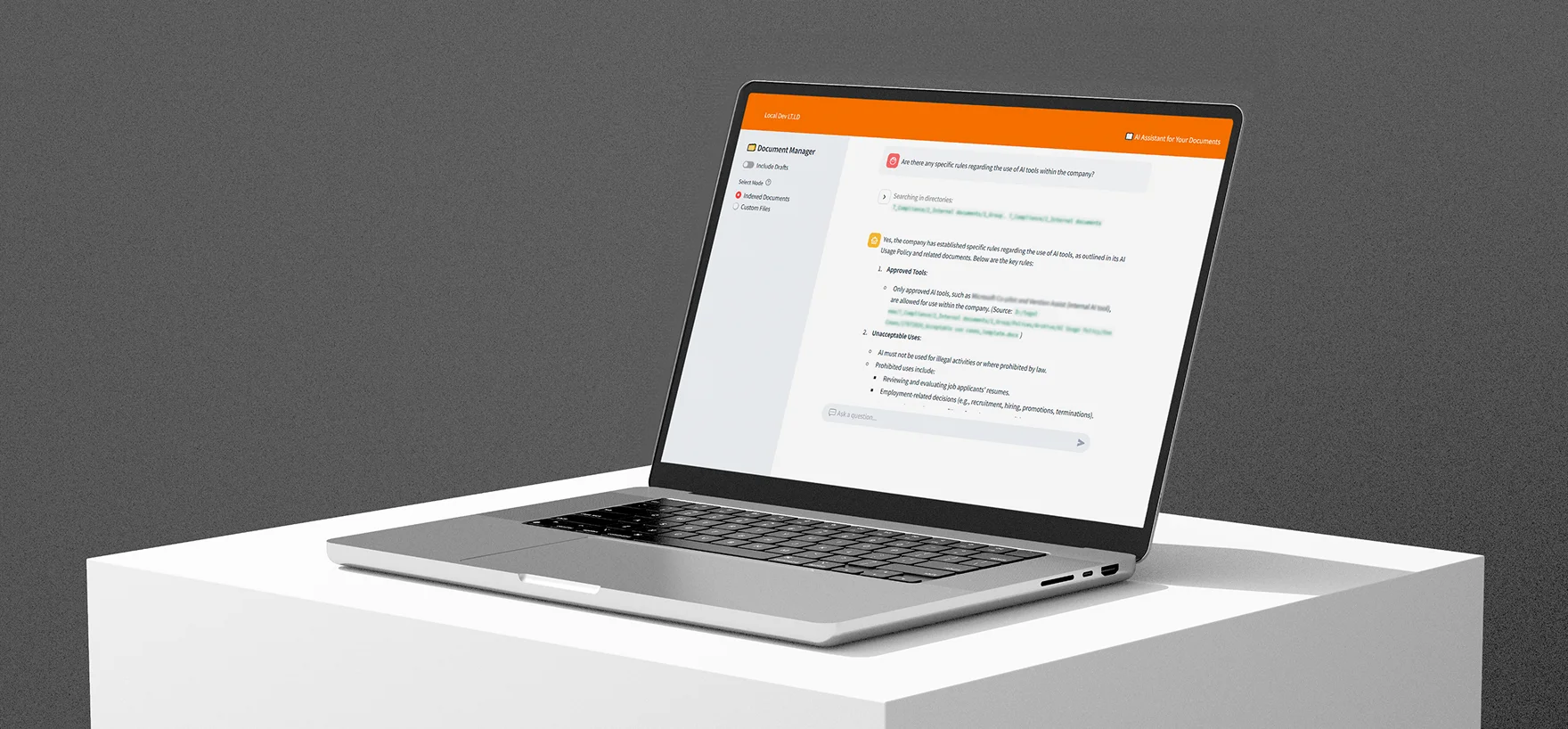
The user interface is the primary point of interaction between users and the platform. It features a design that remains simple and functional.
The interface represents a chat window where users interact with the RAG platform using natural language. It also allows users to include or exclude draft document versions from searches and to define custom file ranges that limit the scope of retrieved information.
Request processing layer
The request processing layer is supported by a set of agents that provide contextual guidance to the RAG core.
When a user asks a question related to a document, client, or region, the interpreter agents perform several steps:
- Check whether the topic is new or part of an ongoing interaction
- Identify the intent of the question and generate a set of semantically related queries
- Break complex requests into smaller, easily manageable actions
- Identify the directories and documents most likely to contain relevant information
- Pass the enriched context to the main language model
The goal of this process is to reduce the retrieval of irrelevant or inaccurate information caused by differences in wording across documents.
For example, a question such as “What is the NDA status of XYZ GmbH?” is interpreted in the following way:
- The system determines that the question introduces a new topic.
- The request relates to a company operating in the DACH region, indicated by the GmbH designation, named XYZ.
- Relevant legal material may include an NDA clause within a contract or a separate NDA document.
- Confirmation is required on the current status of the NDA with the XYZ company, including whether it remains active or has expired.
Based on this interpretation, the processing layer generates related queries such as “Can we disclose our collaboration with XYZ GmbH?” After that, it directs the search toward DACH-related directories and files connected to both Vention and XYZ.
This approach keeps the language model focused on the current context and filters out all unrelated data, which reduces the risk of incorrect responses and improves response time.
More importantly, it allows the platform to identify the most relevant data sources for each request. Legal documents often rely on similar phrasing, which creates unnecessary noise during retrieval. By breaking questions into clear attributes, the system narrows its focus to the relevant documents and delivers accurate results.
RAG core
Once the instructions and the most likely answer sources are prepared and passed to the main language model, the model reviews the provided sources and contextual signals from the processing layer.
Based on this input, the system produces several possible answers for each question, covering both the original user request and the additional prompts created earlier in the process. Then it reviews these options and combines them into one final answer that best matches what the user is looking for.
After the platform returns an answer, users can ask follow-up questions within the same topic, which allows the process to continue while preserving context.
Key stats
Weeks to develop the MVP
Vention AI experts involved
Accuracy across responses
Book a demo session and see how Vention’s RAG platform can help your legal team work smarter. Or tell us what you need, and we’ll tailor an AI solution to your business.
Results
The platform is now live within Vention’s application ecosystem.
Vention’s legal department has already seen significant improvements in daily work. The team is saving 50-70% of the time spent on tasks such as document summarization, document comparison, and creating workflows from documents. With an accuracy of around 88% and response times of three to 10 seconds, the solution supports both deep document review and quick answers when time matters.
Thanks to our RAG platform’s performance, several clients have already expressed interest in using the solution in their own processes. We’re currently scheduling demo sessions and discussing implementation options.
If your team is looking for similar results, Vention is happy to share the real, day-to-day benefits of AI with teams focused on practical outcomes.
Tech stack
GenAI
Vertex AI/Gemini
Frontend
React
Backend
Python
LightFM
Implicit
Pytorch
Databases
PostgreSQL
BigQuery
Redis